
By: Jay Turcot, Lead Scientist
Affectiva’s facial coding and emotion analytics technology (Affdex) relies on computer vision in order to perform its highly accurate, scalable and repeatable analysis of facial expressions.
When consumers participate in an Affdex-enabled experience with a device, it is computer vision algorithms that watch and analyze the video feed generated from the webcam or any other optical sensor.
Computer vision is the use of computer algorithms to understand the contents of images and video. In the case of Affectiva, the computer is replacing the human that would watch for facial reactions (human FACS coders).
Our technology, like many computer vision approaches, relies on machine learning. Machine learning refers to techniques in which algorithms learn from examples (training data). Rather than building specific rules that identify when a person is making a specific expression, we instead focus our attention on building intelligent algorithms that can be trained (learn) to recognize expressions.
At the core of machine learning are two primary components: (1) data: like any learning task, machines learn through examples, and can learn better when they have access to massive amounts of data, and, (2) algorithms: how machines extract, condense and use information learned from examples.
While the algorithms are the students, the data are the teaching materials from which they learn. At Affectiva, algorithms and data are combined into a system that is capable of finding and tracking faces and discerning what expressions are present. In part one of this two-part blog, we’ll discuss the data that drives our latest expression detection improvements.
DATA: SEEING THE FACES THROUGH THE TREES
Humans take for granted how easily we recognize faces and the diversity of faces we encounter in day to day life. Individual faces vary due to physiognomy, wrinkling, aging, gender and race. Cosmetic changes, such as facial hair, makeup, piercings and glasses, can all change the visual appearance of faces. Through daily exposure to thousands of faces, our brains are able to ignore all these superficial variations and see the forest through the trees, recognizing these all as the same thing: a human face.

Machines are exceptionally good at picking out great detail in images. The slightest change in shading is instantly known and quantifiable. Changes to a single pixel can be detected with ease. The challenge is enabling the machine to learn, like a human does, the wide variation that exists in the human face.
Being able to recognize expressions involves learning to accept, account for and ignore all these individual variations. In order for a machine to approach and even surpass a human’s ability to detect expressions, we need it to learn from thousands and thousands of faces of all types. These faces represent the data which is used to train our systems.
HOW MANY EXAMPLES DOES IT TAKE TO LEARN A FACIAL EXPRESSION?
Our tests show that with our current algorithms, we continue to see accuracy improve even as we increase the training set to 100,000 examples. Ongoing improvements to our algorithms can push the upper limit of accuracy and require even more data.
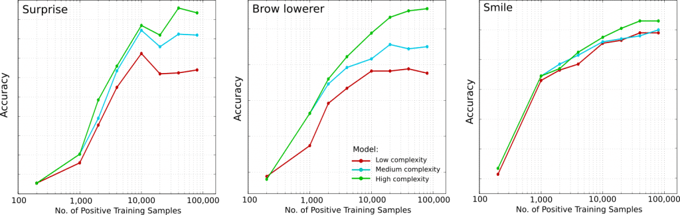
Figure: Examples of expression detection accuracy as we increase the amount of training data. Increasing the data by orders of magnitude helps improve the accuracy for differentalgorithms (low, medium and high complexity).
The challenge then becomes efficiently creating the training data from which our system learns.
Affectiva’s systems are trained on spontaneous data: expressions elicited naturally (“in the wild”), as opposed to posed or acted expressions. As a result, finding relevant examples of spontaneous expressions can be time consuming for humans. At the time of writing, Affectiva has amassed and analyzed more than 2.8 million facial videos, and searching for frames that contain a certain expression is non-trivial. In fact, not only do we need a large variety of different individuals, we also needs thousands of individuals performing a single expression. For example, for the process of learning what frowning is, the system must learn the diverse ways the appearance of a face can change when the lip corners are lowered.
DATA MINING: WHAT IS ACTIVE LEARNING?
In order to find thousands of people frowning, we mine our dataset of over 2.8 million faces, collected from around the world. The goal of the mining exercise is to uncover more examples, and more variation of expressions from which our system can learn. This process makes use of our ever-improving expression detectors to isolate examples where the system is uncertain. Our team of human FACS coders check these expressions and add them to a growing pool of training data. In doing so, they confirm whether an expression is present. In a way, this is like a teacher and a student working through a challenging problem. The teacher (human coders) actively provides guidance to the student (our algorithms). In this way the system continues to improve: a process known as active learning.
This ongoing mining dramatically increases the variation and numbers of expressions our algorithms can learn from. Rather than being taught in an isolated classroom, our models have travelled the world looking at faces. They have been exposed to a variety of peoples, cultures and expressions. Instead of a naive student with their limited world view, Affdex, our facial coding and emotion analytics technology, is now a seasoned globetrotter with years of global facial coding experience.

MAKING THE BEST SCIENCE EVEN BETTER
After months of retraining and experimentation, we’ve recently released an update to our facial coding classifiers – we call this release “PA pack”. These classifiers make use of the spontaneous data that we’ve gathered from around the world in the course of our years in market, and combine them with our ever improving algorithms to give you our latest version. These exciting new classifiers are already available on the Affdex platform, making a difference to our clients as these will allow them to gain higher accuracy faster.
In the next blog I will explore the difference that algorithms make, digging into how the choice of algorithm to use can impact the speed and accuracy of the overall system.




