
Author: Scott Wisdom, Senior Research Scientist at Affectiva
In the past decade, learning with deep neural networks has become the state-of-the-art approach in a variety of applications areas, including image classification, natural language processing, and audio processing. For audio processing, deep learning is setting new benchmarks on audio synthesis, classification, and enhancement. In this post, I’d like to talk about some of my recent work about building new and better types of deep networks for audio tasks, specifically for the task of speech enhancement. Speech enhancement is the task of removing the background noise from an audio recording of noisy speech, which is useful pre-processing for speech emotion classification.
In short, for the task of speech enhancement, my colleagues at the University of Washington and I have shown that better deep network architectures can be constructed using an existing statistical model and inference algorithm. These deep network architectures are better because they allow for the incorporation of priors from existing statistical models, which provides more interpretability of the network weights while also achieving competitive performance with existing state-of-the-art deep network architectures. The material presented in this post was a major component of my PhD dissertation at the University of Washington in Seattle and is the subject of our recent paper at the 2017 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), where we were honored to receive the best student paper award.
Deep networks are very effective because they have the capacity to learn large amounts of information from large datasets. However, one downside of deep networks is that they are unprincipled black box models, as their weights and architecture are not necessarily interpretable physical quantities. Rather, through a long process of trial-and-error combining the cleverness and insight of many researchers, a toolbox of deep learning components has been compiled that tends to work well on many problems. This lack of understandability and interpretability is a major roadblock towards designing better deep network components and understanding better how these deep networks learn to perform so well on many tasks. To address this problem, our approach looks to the recent past to suggest a solution. But to understand our approach, we need to first cover some background material.
Before the explosion in popularity of deep learning, the most effective approach for similar problems was using statistical model-based methods. In this approach, a practitioner builds a statistical model for the particular real-world problem of interest. This statistical model codifies the practitioner’s domain knowledge and statistical assumptions about the data. “Domain knowledge” can consist of any prior knowledge or measurements of real-world phenomena.
For example, in audio processing, practitioners often use the spectrogram to represent and process raw audio signals because it is well known that different types of audio signals exhibit different types of frequency spectra. The spectrogram is computed by taking the magnitude of the complex-valued short-time Fourier transform (STFT), where the STFT is simply the complex-valued Fourier transform of consecutive short frames of the audio signal.
Speech enhancement: extracting speech from noise
To make these ideas of domain knowledge and statistical models more concrete, let’s look at the specific task of speech enhancement. Let’s say that we have observed this speech signal embedded in noise, where the “noise” consists of clanking plates and music in the background:
We artificially created this audio signal by combining a clean speech signal (that is, a person speaking in a quiet room):
with some recorded noise.
If we compare the audio waveforms of these signals:
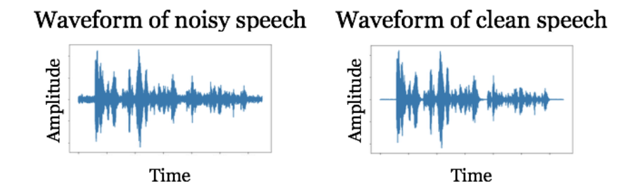
they are different, but it’s hard to imagine how we would directly remove the noise from the noisy speech signal. However, let’s look at spectrograms of these signals:
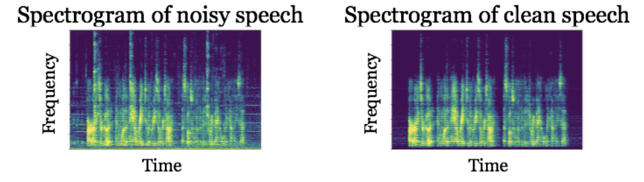
By comparing the two spectrograms, you will notice that the “pixels” of the spectrogram on the left that are dominated by noise are different than those “pixels” of the spectrogram on the right dominated by speech. If we could build a system that determines which “pixels” of the spectrogram are dominated by noise versus speech, then we could build a noise suppression filter from the system’s decisions. This suppression filter can be applied to the complex-valued STFT (recall that the spectrogram is just the magnitude of the STFT; we need to use the complex-valued STFT since its phase is necessary for reconstruction back to the time domain), and an estimate of enhanced clean signal can be constructed by inverting the filtered STFT. This has been the basic idea behind all speech enhancement algorithms since at least the 1970s, which until recently were not able to exploit a large amount of data to learn a better noise suppression rule.
.png?width=644&height=392&name=Screenshot%202023-08-14%20at%2015.20.38%20(1).png)
A statistical model for speech enhancement
One particular approach for speech enhancement that became popular in the mid-2000s is nonnegative matrix factorization (NMF). NMF is a particular statistical model that can be used to build a noise suppression filter in the spectrogram domain. The basic idea is that the spectrogram, which is a matrix of size F by T, where F is the number of frequencies and T is the number of time steps, can be decomposed into a product of two matrices, D and H, where D (the “dictionary”) is a nonnegative matrix of size F by R, and H (the “activations”) is a matrix of size R by T. The columns of the dictionary D represents “patterns” across frequency in the spectrogram, and each row of the matrix H represents the “activation” of a particular dictionary element over time. Also, the activation matrix H is constrained to be sparse, which means that only a few activation coefficients are active at any particular time step. This sparsity constraint ensures that only a few dictionary elements are used to represent each frame of the spectrogram, which forces the model to provide a representation that is as simple as possible. Thus, NMF is modeling each frame of the spectrogram as being composed of a weighted sum of only a few of the dictionary’s patterns across frequency.
To perform speech enhancement with NMF, we can train the dictionary D ahead of time to have two subdictionaries: one subdictionary is trained on a dataset of clean speech spectrograms, and the other subdictionary is trained on a dataset of noise spectrograms. Since speech and noise tend to exhibit different patterns across frequency, these two subdictionaries will tend to be different. In fact, to perform speech enhancement we will rely on the fact that these two subdictionaries contain different patterns across frequency. When we are presented with a noisy spectrogram, we can infer the coefficients H given the D that we have trained by using an inference algorithm that, in our case, minimizes the negative log-likelihood function defined by the NMF model by taking iterative accelerated gradient steps. See our paper for more details on this algorithm, which is known as the iterative soft-thresholding algorithm (ISTA). Interestingly, the nonlinear component of these accelerated gradient steps corresponds to a rectified linear unit (ReLU) function, which is a popular activation function used in deep networks.

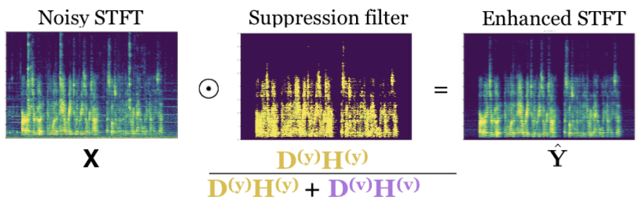
Since D has a partitioned structure, we can then build a suppression filter as a ratio of the speech spectrogram estimate to the sum of the speech spectrogram estimate and the noise spectrogram estimate. This filter can then be applied to the complex-valued STFT, and the enhanced speech can be reconstructed.
Using deep networks for speech enhancement
Recent work using deep networks for performing speech enhancement has essentially adopted this suppression filter approach, except that instead of using a statistical model to infer the suppression filter, a deep network is used. The deep network takes the noisy audio as input, and produces a suppression filter for the STFT. Though this approach mimics the conventional speech enhancement mechanism, the deep networks that infer the suppression filter are not interpretable, and besides using a tedious and exhaustive process of trial-and-error, it is not clear how to improve existing deep networks for speech enhancement.
The best of both worlds: combining statistical models and deep networks for speech enhancement
The main contribution of my recent paper is that we can have the best of both worlds. We show that it is possible to build a new type of deep network that is directly constructed from the computations of an optimization algorithm for the NMF statistical model. That is, the network solves the problem of inferring the NMF coefficients H given an input noisy spectrogram X and a trained NMF dictionary D.
Since this new deep network is constructed using NMF and is both deep in iterations and recurrent in time, we call it deep recurrent NMF (DR-NMF). Because DR-NMF is exactly equivalent to the computational graph of an inference algorithm that infers the NMF activations H, the weights of the DR-NMF network are interpretable as the weights of the inference algorithm and parameters of the NMF model. For example, some of the weights of the network correspond to the NMF dictionary D, which as we saw above, correspond to different patterns across frequency for speech and noise. As another benefit of this correspondence to a NMF inference algorithm, DR-NMF networks can be initialized with a NMF model, instead of being randomly initialized like conventional deep networks. This improved initialization incorporates the prior knowledge of NMF, making sure that the network works at least as well as NMF before being further tuned on a large dataset.
To determine the performance of DR-NMF, we compare it to a conventional deep recurrent network architecture, stacks of long-short term memory (LSTM) recurrent neural networks, that is equivalent as possible in terms of its architecture and number of trainable weights. Using a large speech enhancement dataset from the CHiME2 challenge (the second Computational Hearing in Multisource Environments challenge), we show that DR-NMF networks achieve the lowest average squared-error in the spectrogram domain versus the conventional architecture (0.0266 versus 0.0339). In terms of a commonly-used measure of the quality of separation known as signal-to-distortion ratio, or SDR, DR-NMF networks achieve slightly lower performance (11.31 decibels versus 12.35 decibels). However, when a smaller amount of training data is used (specifically, 1/10 of the training set), DR-NMF networks achieve the best performance, yielding a SDR of 11.12 decibels versus 10.59 decibels. Here are some audio samples:
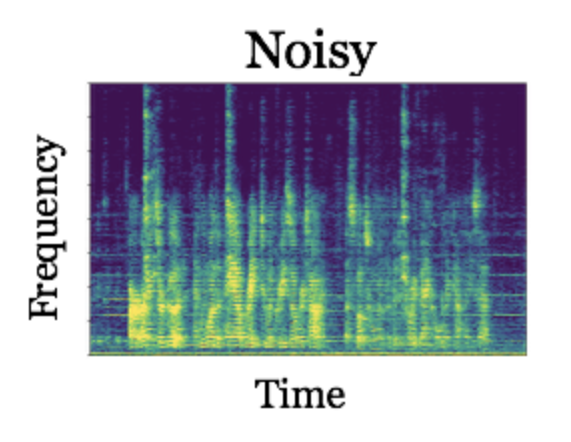
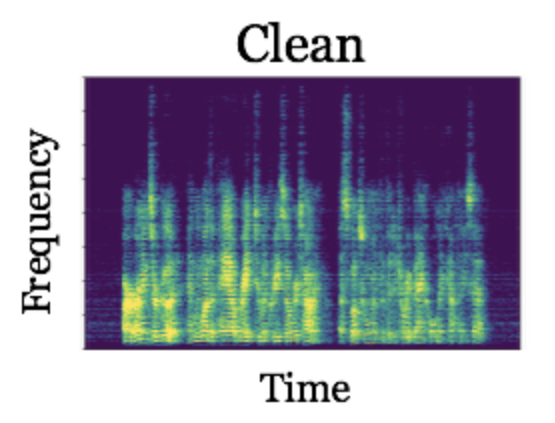
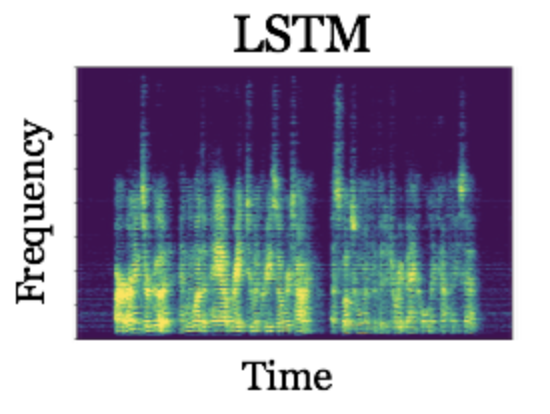
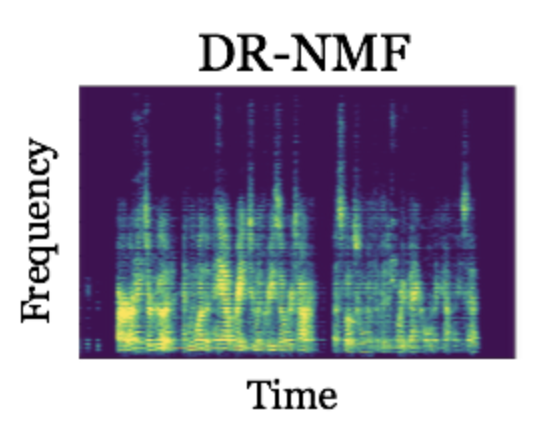
The fact that DR-NMF networks are competitive with a very similar conventional, state-of-the-art deep recurrent network is significant, since it suggests that deep networks constructed from statistical models can achieve better performance using less training data. This is significant because cleanly labeled training data can be very laborious to gather and annotate in many domains. Thus, though building deep networks by combining existing deep learning building blocks can be effective, using statistical model-based reasoning to inform combinations of the existing layers or to even create new deep networks layers can yield dividends, including interpretable network weights, principled initialization schemes, and improved performance when less training data is available.
Conclusion
At Affectiva, we are pushing the state-of-the-art in speech emotion recognition, which inevitably involves important issues such as being robust to background noise.
Read more in the full paper here.
About Scott Wisdom
Scott Wisdom received his BS in electrical and computer engineering from the University of Colorado Boulder in 2010, and his MS and PhD in electrical engineering from the University of Washington in Seattle in 2014 and 2017, respectively. His past industry experience includes working as a software engineer focusing on embedded systems and as a research intern at Microsoft Research in Redmond, WA and at Mitsubishi Electric Research Labs (MERL) in Cambridge, MA. Scott’s research interests include machine learning, deep learning, and statistical signal processing, especially for audio and speech applications, and he has authored over a dozen peer-reviewed papers in these areas.



