

In recent years Affectiva’s Emotion AI evolved to not only measure complex and nuanced emotions and cognitive states, but to also measure what else is happening with people in a vehicle: how are they interacting with the environment and each other, what are their activities and the objects they are using? Our patented deep learning-based software fueled by massive amounts of real-world data, uses in-vehicle cameras to measure in real time, the state of the cabin, and that of the driver and occupants in it.
In 2021, Smart Eye, the leading provider of Driver Monitoring Systems and high-fidelity eye-tracking technology, acquired Affectiva to merge the two companies into a global AI powerhouse. Affectiva’s deep expertise in machine learning, data acquisition & annotation and AI ethics enable Smart Eye to deliver Human Insight AI that understands, supports and predicts human behavior in complex environments.
Affectiva’s automotive technology is now getting integrated into Smart Eye’s innovative Interior Sensing solutions.These insights enable car manufacturers to enhance safety features that meet Euro NCAP requirements.
Consumer rating agencies like Euro NCAP set the criteria for vehicle safety ratings: what for example safety features vehicles need to get a 5-star safety rating. Ultimately, safety ratings can influence the prioritization and adoption of vehicle safety systems, especially as it relates to how OEMs and Tier 1s shape their roadmap. Starting in 2020, Euro NCAP proposed rewarding the vehicle for mitigating driver distraction.
Systems need to evolve to detect more complex behaviors for the next generation of Driver Monitoring Systems (DMS). Driver monitoring should detect complex and nuanced states of driver impairment such as causes of distraction to ensure road safety. Understanding these driver states provides valuable insight into driver interactions with vehicle systems and other passengers to improve road safety.
The Importance of Gaze Estimation in Understanding Driver Distraction
Vehicles equipping advanced driver assistance systems (ADAS) with the ability to detect driver states, such as distraction, can help prevent accidents by understanding if the vehicle’s safety systems need to take over. In order to detect driver distraction, a DMS must be able to monitor their visual attention, then ideally work with an ADAS system to help improve driver safety. OEMs and Tier 1s can then use this gaze information in its simplest form to understand where the driver is looking to determine whether their eyes are on the road or not. Beyond the eyes-on-or-off road scenario, understanding if the driver is distracted due to looking at their phone or elsewhere in the vehicle is important to determine what adaptation the vehicle will take.
Affectiva Publishes Paper with MIT on Innovative Gaze Estimation Approach
Understanding the role of gaze estimation in driver distraction was recently the subject of study for the MIT Age Lab’s Advanced Vehicle Technology Consortium (AVT). This academic industry partnership started in 2015 with the goal of achieving a data-driven understanding of how drivers engage with and leverage things like driver assistance technologies. Using advanced computer-vision software and big data analytics, researchers gather data to quantify drivers' actions behind the wheel. The effort aims to develop human-centric insights that drive the safety efficacy of automated vehicle technology development and advances the consumer's understanding of appropriate technology usage.
Affectiva is a member of MIT’s AVT Consortium, which brings together other key stakeholders in the automotive ecosystem, such as automakers, insurance companies, tier-1 suppliers, and research organizations with the goal of achieving a data-driven understanding of how drivers engage with and leverage vehicle automation, driver assistance technologies (Source: MIT Age Lab).
In collaboration with the AVT, Affectiva has developed a system for driver glance classification. This project was undertaken to enable the AVT to perform gaze based analysis on their robust dataset collected from vehicles not equipped with a dedicated DMS system. Our paper on the topic of driver glance classification in-the-wild has been accepted to FG 2021. The following is a lightweight summary of our findings.
Driver Monitoring Systems: The Role of Gaze and Challenges with MIT AVT’s Data Set
A driver monitoring system is designed and calibrated to tell where people are looking before the driver gets into the vehicle. Popular methods use special hardware calibrated to track eye's cornea reflection to estimate where people are looking.
Affectiva’s In-Cabin Sensing (ICS) solution understands what is happening inside of a vehicle through patented deep learning-based software. Affectiva’s Automotive AI measures in real time, the state of the driver—their complex and nuanced cognitive states, such as drowsiness and distraction—using computer vision, cameras and video imagery.
Our technology, like many computer vision approaches, relies on machine learning. Machine learning refers to techniques in which algorithms learn from examples, or training data. Rather than building specific rules that identify when a person is making a specific expression, we instead focus our attention on building intelligent algorithms that can be trained to recognize expressions.
The MIT AVT dataset was challenged with how to infer where people are looking from recordings done using off-shelf RGB camera, and a system not calibrated for gaze estimation. In our paper, we proposed an end-to-end system to help better understand driver gaze.
What is an End-to-End System?
An end-to-end system is a model that takes input (e.g. an image of the driver's face), processes it and shares the output as a direct target (e.g. glance region). So it works in a stand-alone manner without requiring a pipeline of models.
End-to-end systems can do the targeted task(s) from input to output without requiring help from other components or additional data. For example, this glance classification model directly maps pixels from an input image to a target glance region of interest (hence end-to-end) but a gaze vector based approach requires additional information regarding the car configuration for mapping.
End-to-end systems work in a stand-alone manner and can directly map an input to a targeted output. For example, in our case the input image(s) are fed to the model and it directly maps the pixels to a particular ROI class, without requiring additional information or upstream features from other models.
On the other hand, the gaze vector prediction model we are working right now requires additional information related to cabin to decide on the final ROI class. Our drowsiness estimation model also takes as input model predictions from our SDK classifiers, and not image pixels, while estimating the drowsiness state of the driver.
Since end-to-end systems work in a stand-alone manner, they can be beneficial to DMS systems independent of other associated models.
The Challenges in Understanding Driver Gaze Estimation
Understanding driver gaze associated with an end-to-end glance classification system presents a number of challenges.
First off, while professional gaze tracking systems do exist, they typically require user-specific calibration to achieve good performance.
Next, Driver Monitoring Systems are either a single universal model or a collection of different models that do different tasks. One of such tasks can be glance classification, and our model can be used for this purpose. Other DMS models that make predictions based on only a single static frame may struggle to deal with variations in subject characteristics not well represented in the training set. For example, if the training set only has tall people and you train the glance classification model with such data, the model might not perform so well during testing if a short driver is being monitored. Given how that driver's head will be located within the car, the model might perform poorly, given the taller heads it had seen during training.
Another challenge is the variation in camera type (RGB/NIR) and placement (on the steering wheel or rear view mirror). Due to variations in cabin configuration, it is impossible to place the camera in the same location with a consistent view of the car interior and the driver. Therefore, a model trained on video frames captured from a specific camera-view may not generalize to other camera angles.
Camera placement is a challenge because depending on where the camera is placed, the driver looks a certain way while glancing towards a particular ROI. For example, if you look at Fig. 4, the leftmost column image captures the lady looking towards the road, with the camera placed on the steering column (SC). But the image of the man in the middle column was captured with a camera placed on the rearview mirror (RVM).
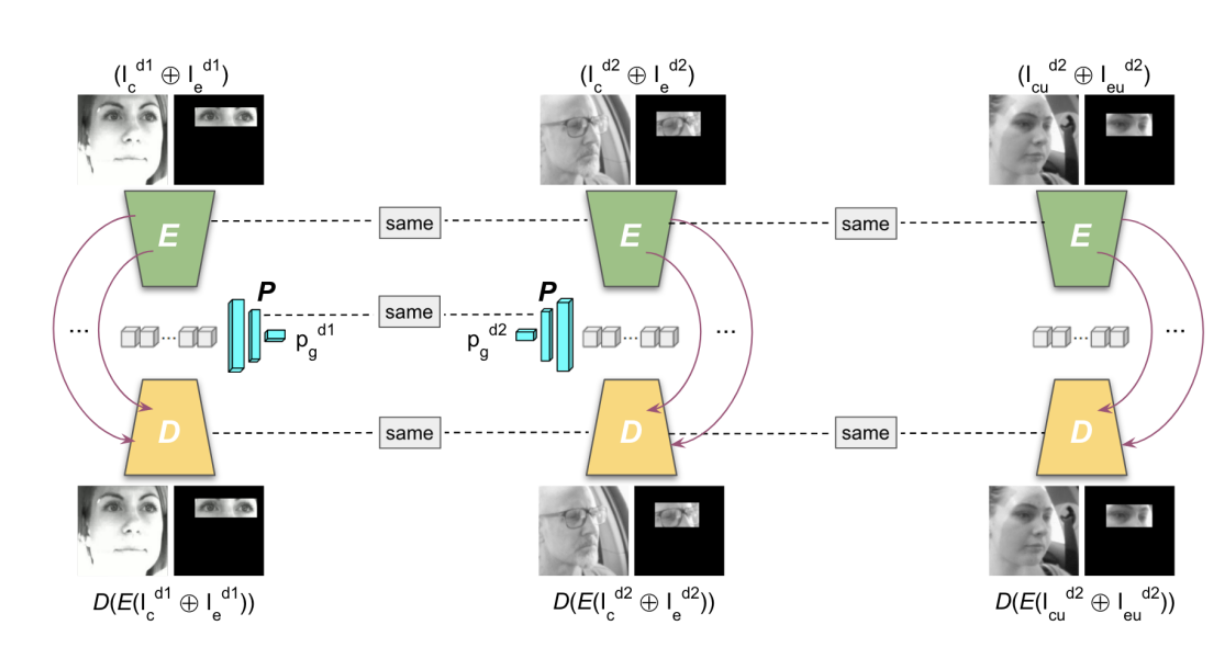
Both the lady and the man are actually looking towards the road i.e. same glance ROI. However, visually they look different, and unless explicitly designed, our model will not do well in classifying these images accurately from the different angles. We can always train different models for different views (i.e. one for SC view, another for RVM) but that adds to the computational complexity and is not an elegant solution. Hence, we have designed a domain invariant training approach that enables us to train the same model to reliably work on frames captured from different camera angles.
The Affectiva Approach to Gaze Estimation
Affectiva proposed a framework to jointly train models using data from multiple varying sources, such as camera types and angles. This framework utilizes unlabeled samples from these multiple sources along with weak machine learning supervision from any labeled sample to improve glance classification. This approach also effectively reduces the labeling cost, as data needed to fuel the algorithm doesn’t need to be fully annotated.
The model we proposed takes as input a patch of the driver’s face along with their eye-region, and classifies their glance into 6 coarse regions of interest in the vehicle. To make the system robust to subject-specific variations in appearance and behavior, the model we designed was tuned with an auxiliary input representing the driver’s baseline glance behavior. Finally, a weakly supervised multi-domain training regimen enables the network to jointly learn representations from different domains (varying in camera type, angle), utilizing unlabeled samples.
The Results
Our framework, through leveraging unlabeled data during model training, improved accuracy over models trained with the same set of labeled data. This network model outperforms currently published results on an MIT “in-the-wild” driving dataset: 20 subject tests demonstrated a 65% reduction in errors, with an accuracy of 96.5% (Affectiva approach) vs. 90% (MIT’s original approach). Our method also outperformed other recent methods from researchers at UC San Diego and BMW. In essence, researchers at MIT can now, with higher confidence, analyze the driver gaze behavior on their AVT dataset.
The Bottom Line
While this isn’t a formal depiction of how the Affectiva Automotive AI product is designed, the concepts illustrated in this paper demonstrate the ingenuity of the Affectiva team to approach a problem and develop a highly accurate, cost-effective solution. Using the MIT AVT data set, we were able to train a model for gaze detection using both labeled and unlabeled data from multiple data sources within the cabin. Affectiva’s model design led to comparable accuracy with a fully labeled data set using fewer labels. This work is just an example of how Affectiva is looking to advance semi-supervised learning as a method for developing cost-effective machine learning based automotive technology.
To read the paper in full, go here: Driver Glance Classification In-the-wild: Towards Generalization Across Domains and Subjects




