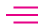

You may have caught that Affectiva recently surpassed over 5 million faces analyzed. What we define as faces are really “face videos”, or video recordings of people as they go about an activity. Affectiva collects these face videos through our work with market research, automotive, and robotics partners.
In order to find thousands of people smiling or smirking, we mine our data set of over 5 million faces from all over the world. The goal of the mining exercise is to uncover more examples, and more variation of expressions from which our system can learn. The process of labeling provides examples to bootstrap new classifiers, as well as improve existing classifiers. For example, if we need to develop a new “Wink” classifier, a pool of videos will be imported from data sets that are more likely to have people “winking”, then the data is used to train a new classifier. The developed classifier can then be used to mine more videos extracting “wink” segments. Those segments get imported for labeling and re-training the “wink” classifier. This feedback loop between the classifiers and the labeled data help improving expression detectors to isolate examples where the system is uncertain.
That means there are 2 types of data that we import for labeling:
- Set of videos that we need to explore different expressions in (no mining is included)
- Videos that are mined for certain expressions to improve their existing classifiers
The labeling process is done by our team of human FACS coders who check the imported data and annotate it to get added to a growing pool of training data. In doing so, they confirm whether an expression is present. That labeled data serves as the ground truth against which the algorithm is tested. In a way, this is like a teacher and a student working through a challenging problem. The teacher (human coders) actively provides guidance to the student (our algorithms). In this way the system continues to improve: a process known as active learning.

Let’s take a step back: why is labeling so important?
For our business, face video analysis is critical to not only ensure the accuracy of our product, but to continuously improve the algorithms that fuel it. How do we deliver on the promise of the most accurate facial expression & emotion recognition data available? Our amazing labeling team.
Labeling provides ground truth data. Humans are the best at noticing expressions and interpreting emotions, but our algorithm classifiers must be trained to pick up on what humans are able to do automatically. What our labeling team does is similar to the teacher - student interaction: in order to teach the students, you must give them examples of smiles, across gender, age ranges, and cultures. There are many different flavors of smile depending on where a person is from: for example, a smile tends to be less intense on those from Japan than on people in the Middle East or US. It’s important to note these various examples of smiles so our algorithms wouldn’t miss certain expressions, or low-intensity expressions. So by providing this manual ground-truth data (this is a smile, this is not), our labeling team is able to continuously train our machine learning techniques - to continuously train our (supervised and semi-supervised) machine learning techniques.
The Science of Affectiva’s Facial Action Unit (FACs) Labeling
- Opting In. First off, all of our faces that we have analyzed have explicitly been asked to opt in to have their face recorded and their emotional expressions analyzed. We recognize that emotions are private and not everyone wants their face recorded. In addition, data collection is anonymous, we never know who the individual is that the face belongs to. Lastly, this data is proprietary, so we do all of our labeling in-house instead of outsourcing - this also helps us ensure high, controlled quality.
- “In the wild” Data. Our emotion database is the result of spontaneous data collected in the real world, or what we call “in the wild”. The data is representative of people engaging in an activity, wherever they are in the world – at their kitchen table in San Francisco or on their couch in London. The face videos also represent real, spontaneous facial expressions: unfiltered and unbiased emotions in reaction to the content these folks are watching or the thing they are doing. Also, this data captures challenging conditions, such as variations in lighting, different head movements, and variances in facial features due to ethnicity, age, gender, facial hair and glasses.
Facial action coding (FACs) labeling
All labelers we hire are trained in FACs: meaning they have taken a course and received 100s of hours training on the science that studies movement of each action unit of the face, as well as what those movements mean in relation to the intensities (and resulting emotion) of those groupings of facial movements.
We use Paul Eckman’s science as a standard for analyzing combinations of specific Action Units (AUs). His system, EMFACS, provides instructions on how each of these AU combinations map to specific emotions. For example, Happiness is defined as AU 6 (cheek raiser) + AU 12 (lip corner puller).

How we decide what to label
Our science team decides on data set we want to import to the labellers, as well as identifies which AUs we want to develop data for. Occasionally, the science team will give labellers customized, very detailed instructions for labeling action units, then provide the mapped emotion labeling (joy, fear, etc.) to find the emotions expressed in the AUs.
Our Labeling Methodology
Affectiva-developed labeling system: ViDL
ViDL is a web tool Affectiva has developed internally to label images and videos. For images, labellers can allocate facial features coordinate positions, and this kind of information can help train face detectors and facial landmark tracker. Some other options that a labeler can label in an image:
- Label if the face is occluded or not
- Is the face dark?
- Is the face blurry?
- Is the participant wearing glasses?
- What is the gender of the participant?
- What is the location? Is it indoors or outdoors? In the city, or outside?
- Is the picture crowded?
From videos we can extract emotions (anger, contempt, fear, disgust, joy, sadness, surprise), and the corresponding AUs that make up those emotions:
Emotion |
Action Units |
|
Happiness |
6+12 |
|
Sadness |
1+4+15 |
|
Surprise |
1+2+5B+26 |
|
Fear |
1+2+4+5+7+20+26 |
|
Anger |
4+5+7+23 |
|
Disgust |
9+15+16 |
|
Contempt |
R12A+R14A |
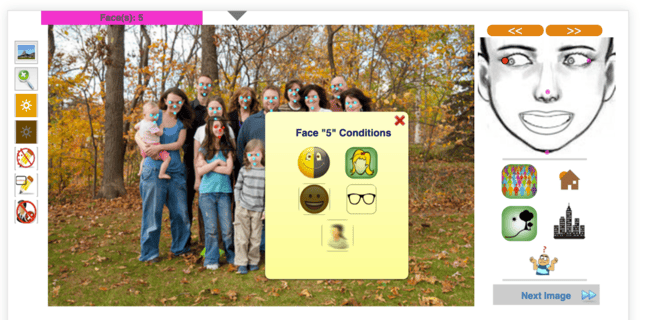
We also label for:
- Appearance (such as ethnicity, age, gender)
- Different actions (like yawning, eating, drinking, smoking, speaking)
- Location (in car, in office, outdoors, at home, etc)
- Indicate if an AU has occurred in a segment of video by the labeler selecting positive (AU occurred) or negative (no AU occurred).
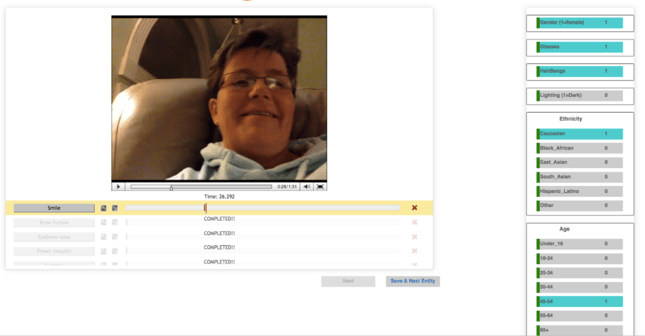
How we label
Per each video segment, we have 10 labellers available to review the face recording. We first import the facial video data and decide on which AUs we need to label - typically per request from our science team. Our labeling team has a reporting system that analyzes the accuracy of each labeller on which labellers are most accurate on which AUs (Labeler 1+2 are both great at finding nose wrinkle, while labeller 3 is more in tune with lip pucker), and divide the AUs accordingly among the team. This assignment system allows us to generate a high rate of accuracy, and can also be applied to ethnicities and age range detection.
From there, each video is labeled by 3 labellers. If the assignment is to label for smiles, the majority or more than 50% of the labelers should agree that a smile has occurred in order for the machine learning algorithms to consume it as an actual smile. If the agreement between labelers is less than 50%, but greater than 0%, the segment will then be marked as a confusing example. If none of the labelers marked a smile, the algorithms will treat those segments as a segment with no smiles.
Then QA goes in and checks the work of the labellers, and either accepts the work, or rejects it by indicating an expression was missed. This feedback loop process helps assure the most accurate depiction of facial expression detection available. Our science team will then consume that data.
Our QA page
Prioritizing Labeler Time with Active Learning
Before we import video and request the team to label it, we can run it through our classifier technology to figure out frames that require human labeling. This capability helps when we need to run active learning mining for a certain expression. Passing the videos through classifiers helps avoid labellers wasting their time on video with no content. We can also use this system to identify and teach the classifiers to better identify AUs.
For example, if the science team is interested in the Disgust emotion for a particular data set, the facial video will run through classifiers to search for AUs that are related to Disgust, or AUs that are part of the emotion combination (In this case, Disgust contains AU 9 (nose wrinkler). Also, if we are interested in a specific AU, we can mine for another AU that frequently coincides with the AU that we are interested in. (For example, if we want to mine for “lip pucker” we can also mine for “mouth closed”.) The labeller then reviews what the classifier has identified, and confirms / rejects the findings so the classifier can be re-trained with this data. This process of active learning helps the classifier continuously improve itself by seeing examples of what it is or isn’t doing correctly. Active learning is so essential to speeding up our labeling efforts by focusing labellers on labeling only what is necessary, avoiding hours of wasted time on unusable video.

We couldn’t do what we do without our Cairo labeling team!




