
Affectiva’s emotion database has now grown to nearly 6 million faces analyzed in 75 countries. To be precise, we have now gathered 5,313,751 face videos, for a total of 38,944 hours of data, representing nearly 2 billion facial frames analyzed.
This global data set is the largest of its kind – representing spontaneous emotional responses of consumers while they go about a variety of activities. To date, the majority of our database is comprised of viewers watching media content (i.e, ads, movie trailers, television shows and online viral campaigns). In the past year, we have expanded our data repository to include other contexts such as videos of people driving their cars, people in conversational interactions and animated gifs.
Transparency is really important to us at Affectiva, so we wanted to explain how we collect this data and what we do with it. Essentially, this massive data allows us to create highly accurate emotion metrics and provides us with fascinating insights into human emotional behavior. Let’s explore this some more.
So how do we collect this emotion data?
Where this data comes from
We have now gathered 5,313,751 face videos for a total of 38,944 hours representing about 2 billion facial frames analyzed. “Face videos” are video recordings of people as they go about an activity such as watching online videos or driving a car. Affectiva collects these face videos through our work with market research partners, such as Millward Brown, Unruly, Lightspeed, Added Value, Voxpopme and LRW, as well as partners in the automotive, robotics and Human Resources space. This data is spontaneous and collected in natural environments: such as people in their home, at their office in front of their devices, or in their car. As a matter of fact, we have already analyzed over 4.4 million frames of emotion data captured from people driving their cars.
Opt-in
It is important to note that every person whose face has been analyzed, has been explicitly asked to opt in to have their face recorded and their emotional expressions analyzed. People always have the option to opt out – we recognize that emotions are private and not everyone wants their face recorded. In addition, data collection is anonymous, we never know who the individual is that the face belongs to.
Spontaneous data, gathered in the wild
Affectiva’s huge emotion database is the result of spontaneous data collected in the real world, or what we call “in the wild”. The data is representative of people engaging in an activity, such as watching content, wherever they are in the world – at their kitchen table in Bangkok or their couch in Rio de Janeiro. The face videos also represent real, spontaneous facial expressions: unfiltered and unbiased emotions in reaction to the content these folks are watching or the thing they are doing. Also, this data captures challenging conditions, such as variations in lighting, different head movements, and variances in facial features due to ethnicity, age, gender, facial hair and glasses.

There are other data sets available that are often developed in academic settings, and almost always collected in lab environments with controlled camera and lighting conditions. These data sets also often capture exaggerated expressions: people are asked to show certain emotions, which creates what we call “posed” data. Frequently these academic data sets introduce bias because test subjects are often from the student body and represent a certain demographic (e.g. college students, age 18-22, caucasian, male, etc.). When you train and test against these posed datasets your accuracy may be high, but real world performance is poor due to the biased data and thus biased software that has been created.
The Global Diversity of our Data
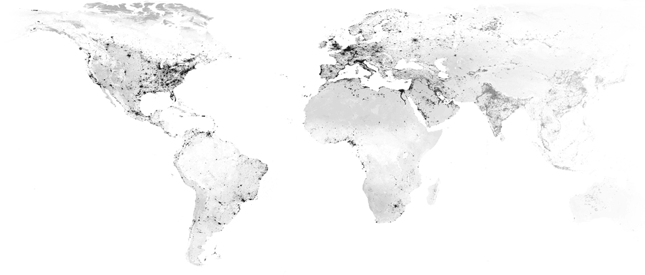
As mentioned, we have gathered this data in over 75 countries. There’s a lot of diversity in this data. This is important because people do not look the same around the world: there are differences in age, gender and ethnicity - and our data is representative of those demographics and cultural diversity. As we are a US-headquartered company, it can be easy to assume most of our data comes from North America or Western Europe. That is not the case. In fact, this is the top 10 of countries we get the most videos from:
India |
1,064,788 |
USA |
956,311 |
China |
502,490 |
Indonesia |
284,015 |
United Kingdom |
264,957 |
Brazil |
176,138 |
Thailand |
162,037 |
Philippines |
133,396 |
Vietnam |
130,610 |
Germany |
125,876 |

The fact that we have such great representation in Asian countries is critical: these geographical areas represent cultures that tend to dampen their expressions (for example, the “polite smile”). This is in contrast to more individualistic, western countries like the US, where people often amplify their emotions, especially in group settings. As a result, we’ve seen that culture has an influence on intensity of emotion expressed. With this global data we can train our algorithms for this so we are uniquely able to identify nuanced and subtle emotion with high accuracy.
What we do with this data
Train and test our algorithms.
Our science team has built a robust infrastructure using machine learning and deep learning methodologies that allow us to train and test our algorithms at scale. So, how do you train a machine to recognize emotions, to distinguish between a smile and a smirk? You feed your learning infrastructure many examples of a smile, and many examples of a smirk. The system identifies the key characteristics of each emotion, and it learns, so the next time it sees a smirk, the algorithm says: “Aha, I have seen this before! This is a smirk.”
We use our facial video repository to train and retrain our facial expression algorithms, also known in Machine Learning language as classifiers. This is actually an incredible notion that our technology works as a positive feedback system – growing more intelligent every day by looking at more of its own data. To enable this, we’ve built the first version of something called Active Learning, a software system that automatically decides which data can help the system improve more rapidly – this is machine learning with big data.
In order to find thousands of people smiling or smirking, we mine our dataset of nearly 6 million faces from all over the world. The goal of the mining exercise is to uncover more examples, and more variation of expressions from which our system can learn. This process makes use of our ever-improving expression detectors to isolate examples where the system is uncertain. Our team of human FACS coders check these expressions and add them to a growing pool of training data. In doing so, they confirm whether an expression is present. That labeled data serves as the ground truth against which the algorithm is tested. In a way, this is like a teacher and a student working through a challenging problem. The teacher (human coders) actively provides guidance to the student (our algorithms). In this way the system continues to improve: a process known as active learning.
This ongoing mining dramatically increases the variation and numbers of expressions our algorithms can learn from. Rather than being taught in an isolated classroom, our models have travelled the world looking at faces. They have been exposed to a variety of peoples, cultures and expressions. Instead of a naive student with their limited world view, our emotion recognition technology is now a seasoned globetrotter with years of global facial expression analysis.
Build industry-leading norms and benchmarks
Our dataset has also allowed us to build what is by far the world’s largest facial expression normative database, a benchmark of what responses to expect in each region of the world. We mine our data to understand the way emotion is expressed across cultures and are seeing fascinating differences – for example, how Americans emote versus viewers in Southeast Asia. It’s also necessary in examining how certain factors (whether we’re collecting data from people’s homes or in venue) and the type of content people are watching (e.g., ads, movie trailers, TV shows) affect the expression of emotions. We have exposed these norms in our market research product, so that our clients can benchmark the performance of their ads based on geography, product category and media length. No other emotion analysis vendor provides these type of norms.
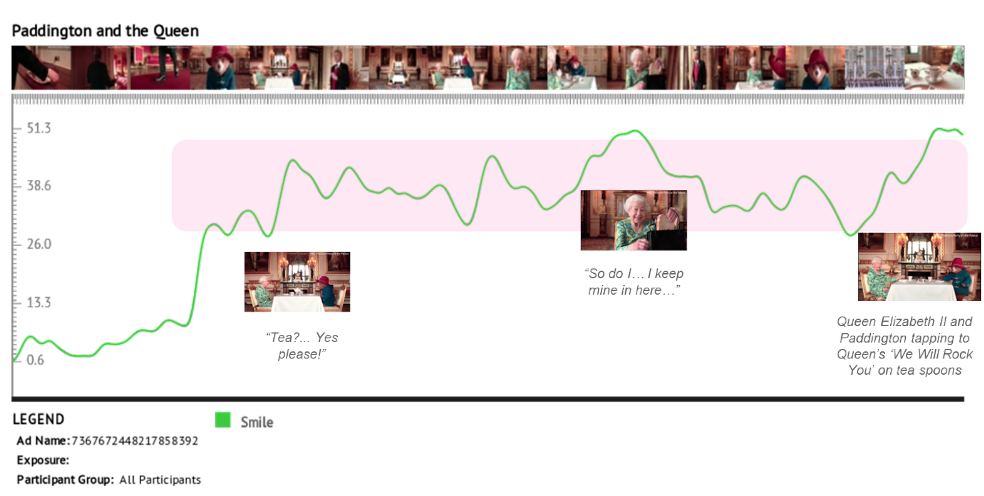
Example of norms in our Affdex for Market Research product
Mining for cross-cultural insights
Lastly, we get some really amazing insights when we mine this emotion data. We are sitting on a rich treasure trove of insight into human emotion responses by gender, age, culture, and geography.
There are interesting insights we have found when we dig deeper into gender and cultural aspects, enabling us to get a better understanding of what it is that women and men respond to differently around the world.
- Women are more expressive than men. No surprise here, but our data also shows that women not only smile more, but their smiles last longer. Tweet
- In one study we did with 1,862 participants we actually saw that women smiled 32% more than men, and that men showed 12% more “brow furrow” (a prototypical expression of anger) than women. Tweet
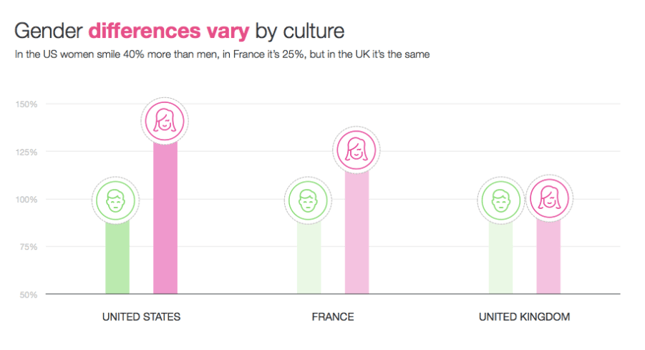
- In the US, women smile 40% more than men, but curiously in the UK, we found no difference between men and women. Tweet
- Women in their 20s smile much more than men the same age - maybe this is a necessity for dating? Tweet
- The Spanish are more expressive than Egyptians, but apparently Egyptians show more positive emotion. Tweet
- People 50 years and older are 25% more emotive than younger people. This surprised me personally as I assumed it would be the inverse. Tweet
- It also turns out we are quite expressive when we’re sitting in front of our devices alone! And it’s not just watching cat videos on Facebook! We express emotions all the time, when we’re emailing, shopping online or even doing our taxes! Tweet
- How social a setting is also influences people’s expressions. In formal group settings, such as a research lab or focus group, people from Asian cultures tend to be less expressive, and people from Western cultures tend to be more expressive. These differences are much smaller in informal settings, such as at home. Tweet
How Far We've Come
Six years ago Affectiva had about 25,000 face videos. Three years ago that number grew tenfold to 250,000. Then in 2013, we hit the one-million mark, which we took as a sign of the unprecedented growth and adoption for Affectiva. And, just recently, we hit the 5 million mark. I received a report yesterday: we have now analyzed 5,313,751 faces. Our database grows every single day.
What's Next?
We believe this is only the beginning. Our vision is to humanize technology with Emotion AI, ensuring that the smart devices and advanced AI systems that surround us, can read our emotions and adapt to these emotions. And, that we can continue to measure with high accuracy how consumers respond to digital content. As we keep growing our emotion database, we are gaining more data in specific contexts, such as videos of people in conversational interactions, animated gifs and people driving cars.
I imagine a future in which Affectiva enables people to build their emotional profiles, that they can then take with them across the devices and digital experiences they use in everyday life – it will be our emotion passport that makes our digital journeys more personalized, effective and authentic.
We are keen to develop more data partnerships to continue to develop this world-class emotional database: if you are interested in working with us on this, give us a shout!