
This is the third post of the Science Deep Dive series. In the last post we talked about addressing the complexities of Emotion AI through Affectiva’s data strategy.
Now, the second step to address those complexities is to use machine learning algorithms, a variety of deep learning, computer vision, and speech processing approaches to learn from our data. Affectiva has developed algorithms to model complex and nuanced emotional and cognitive states.

WHAT DO OUR ALGORITHMS DO?
For our algorithms, 100% of our research is on deep learning technologies. Since 2009, deep learning has basically taken the machine learning world by storm - why? Deep learning so far has shown almost no upper limit in terms of the complexity problems it can model and tasks it can perform. Deep learning is also well suited for end-to-end learning: ingesting audio and video and just model it completely inside this single black box algorithm.
Take a look at our pipeline for example. We do a lot of different tasks: detect the face, detect when a person is speaking, analyze and classify the face, estimate demographics, estimate age, etc. There are deep learning models and approaches for each of those tasks; it solves many problems by analyzing images, videos, and audio files.
DEEP LEARNING ALGORITHM: ARCHITECTURE
When you use a deep learning network, it is a neural network, and the architecture of it is the makeup of that neural network. You have a few trade offs with the structure, especially with regard to how many layers it has and how big those layers are. These aspects come into play when considering how fast it can run to fulfill our on-device strategy (more on that later) versus making it deep / big / complex enough to model all the complexities we want it to model. We're always experimenting different deep learning architectures, different and new components within these architectures, and ways of putting them together to achieve the capability of performing all the different tasks as accurately and as efficiently as possible. We are currently doing a lot of research on the different architectures used to detect faces (as well as other objects), detect facial actions (i.e., expressions of emotion or yawning), and modelling speech through analysis of audio.
It is important to push the limits of the architecture to make it do lots of things simultaneously, and to leverage all these simultaneous tasks to come up with really accurate estimates, really quickly. RPN stands for Region Proposal Networks, which are used for image analysis. RNN (Recurrent Neural Network) within LSTM, is a long/short-term memory recurrent neural network. All of these are different deep learning approaches are meant to solve different tasks.
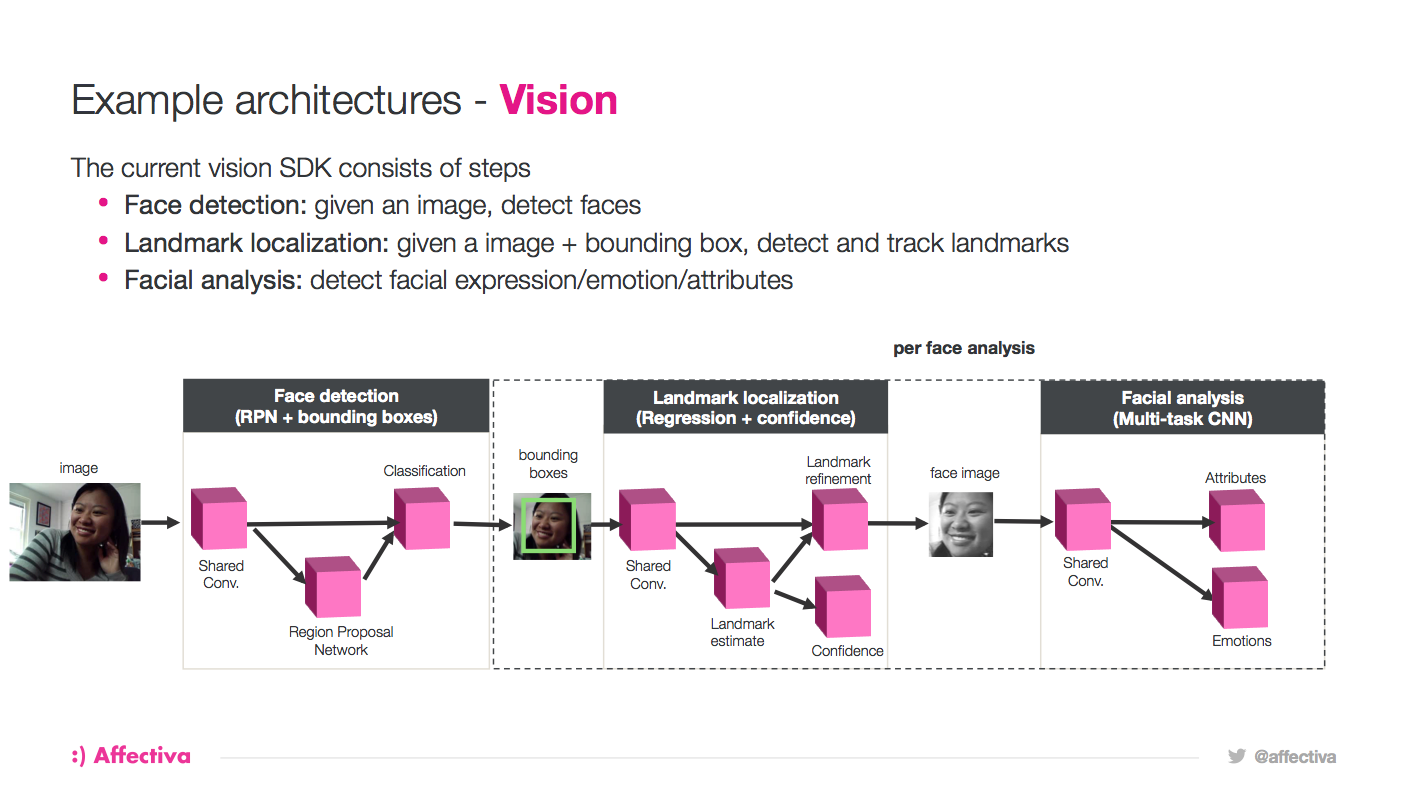
This is how our current vision pipeline looks, pictured above. For this fast face detection architecture, we use a region proposal network combined with this shared convolution, shared information extraction that then feeds an ultimate face or no-face classification. From there, we do fast landmark localization that allow us to know if we tracking the person or not. Once we know where the person’s face is in high fidelity, we try to estimate the expressions they are making, their attributes, and their emotions.
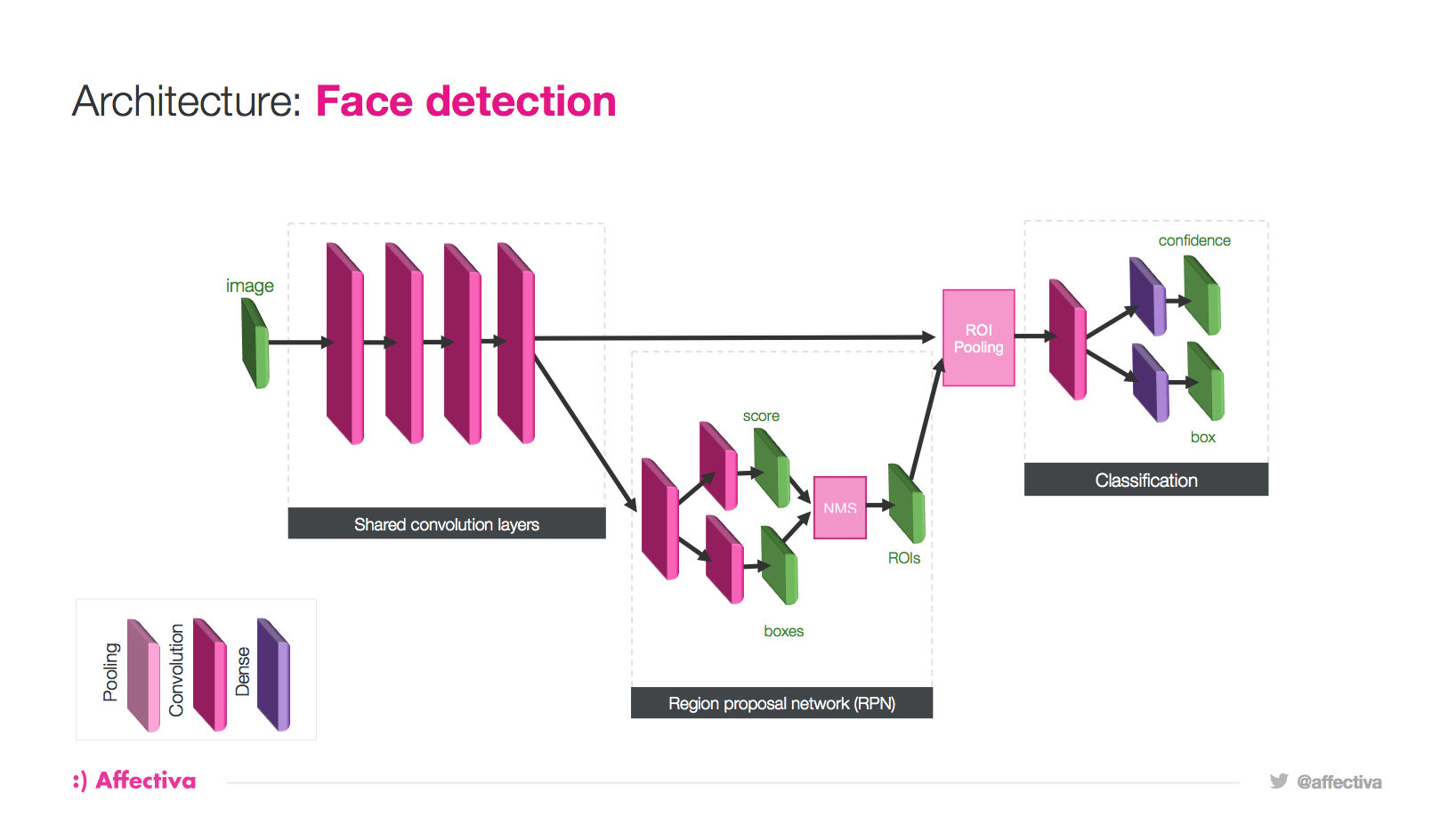
This diagram above an example architecture for face detection. The level of detail and the specific numbers are actually part of the secret sauce.
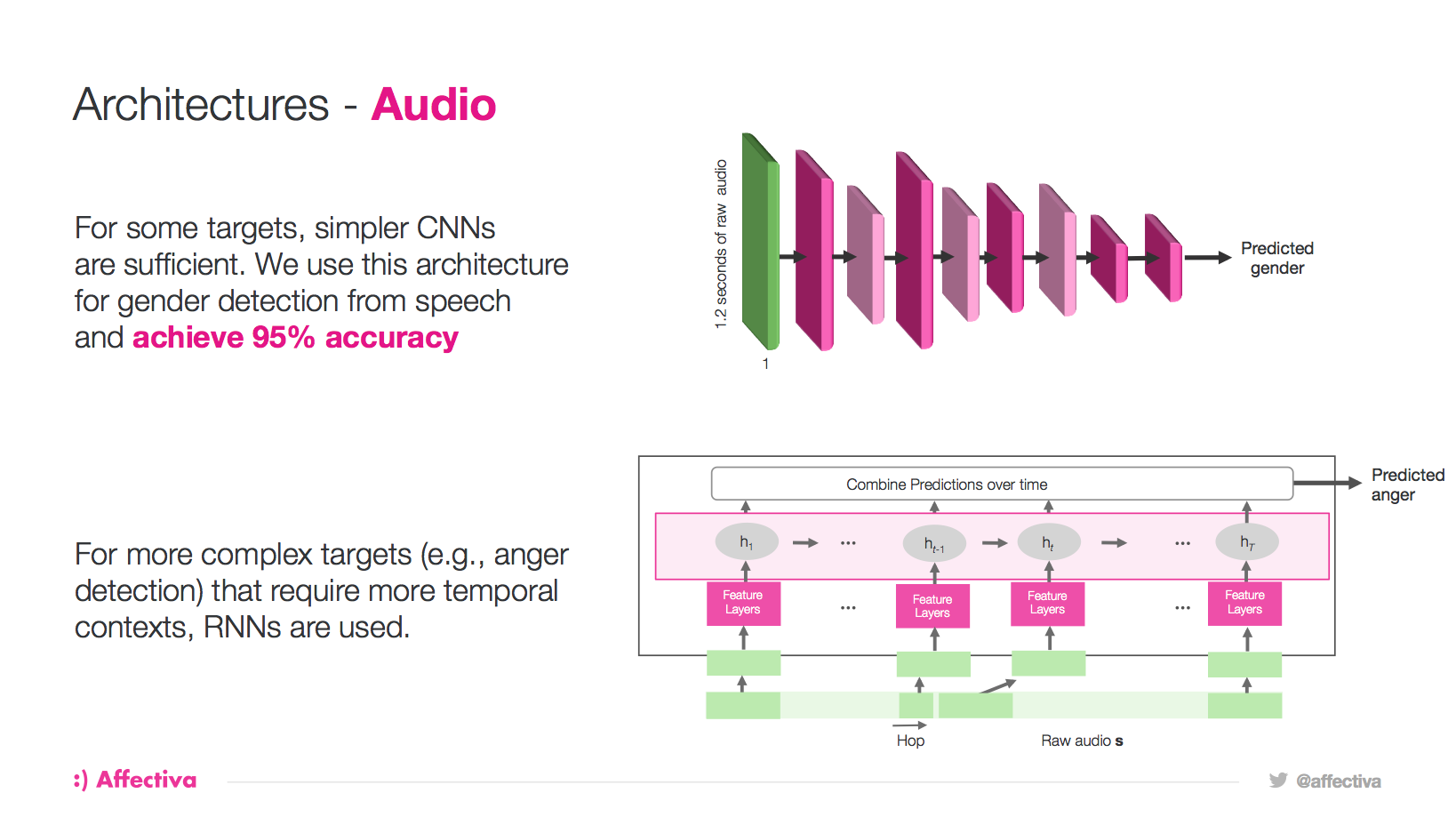
In the audio architecture, we use convolutional neural nets for simpler classification tasks that can just look at a short snapshot of time. For others that need more complex models that need to look at longer periods, like sentence-level estimation, we use recurrent neural networks.
Learn more in the full science deep dive webcast recording:




