
During the 2018 NVIDIA’s GPU Technology Conference (GTC) last month, one of Affectiva’s Product Managers, Abdelrahman Mahmoud, and Computer Vision Scientists, Ashutosh Sanan, presented a very interesting technical session, "Building Emotionally Aware Cars,"where they talked about in-cabin sensing and what is needed to build a platform solution such as Affectiva Automotive AI.
As an Emotion AI company, Affectiva uses deep learning algorithms and lots of naturalistic data to develop platforms that sense people’s emotions through face and voice analysis. Since 2011, we have been in market offering Emotion AI base products - for example, we have helped about ⅓ of the Fortune 100 companies throughout the world to test people’s emotional response to their brands and ads. And now, we are even more excited to share our work with OEMs and Tier-1 Suppliers on the next generation of in-cabin sensing using our deep learning-based platform.
In case you missed it, here were some of the main takeaways during their presentation: (and you can watch the full talk here)
ADDRESSING CURRENT OEM PROBLEMS: DRIVER SAFETY AND OCCUPANT EXPERIENCE
In the automotive segment, our focus is to help OEMs address two main challenges regarding safety and overall ride experience. While introducing our solution, we referenced Lex Fridman’s session at GTC, which addressed the importance of human-centered AI and how we currently live (and will live for a while) in a world where humans and machines have to interact daily. That is the first problem we are looking to address with Affectiva Automotive AI: how to solve the human-robot interaction problem both inside and outside the car (also known as the L3 handoff challenge).
The second challenge OEMs face in this world of highly automated vehicles is how to develop “People Analytics” (real time data that identifies different nuanced emotional and cognitive states from people’s face and voice in real time) or how to use People Analytics to provide actual feedback for the cars to act - whether it is to recommend content or to adjust the in-cabin environment by providing a better ride experience. Affectiva aims to build a two-way trust between the autonomous vehicle and the driver/passenger.
We started by just focusing on people’s emotions from face to voice, and ultimately, we will get facial nuances and cognitive states. For both, it is crucial to take into account not only the interaction between person and car, but also track emotions longitudinally to create an emotional profile. Some other indispensable factors to take into account are the time of the day and the person’s specific likes and dislikes. Taking into account all of this will help to drive use cases for cars around safety and personalization to provide a more enjoyable and comfortable experience to the occupants.
SOLVING EMOTION AI COMPLEXITY
Detecting people’s emotions and cognitives states in the car is no easy task - there are many data challenging conditions that happen while driving: quick transition of emotional expressions, variations in lighting, different head movements, face exiting the camera, and variances in facial features due to ethnicity, age, gender, facial hair and glasses. Our approach to solve such problem consists in 4 key areas: data, algorithms, architecture, and team. For data, we have collected 6.5M face videos from 87 different countries so far. This is the biggest spontaneous emotion dataset that exists today, and this data allows us to teach AI what human facial expressions look like “in the wild” (real, unfiltered and unbiased emotions in reaction to driving) and in different age groups, ethnicities and gender. Additionally, we invited many drivers with kits around the world to commute over the course of a week or more to augment our dataset with spontaneous driver and occupant data, making sure the AI works in the whole complexity of a car. The second approach to addressing the Emotion AI complexities of in-cabin sensing is algorithms (keep reading for more specifics on how we use deep learning algorithms and real life examples.)
Having all this data is not enough to address this complexity - and that’s where the third pillar comes into place: infrastructure. We focus on linking the infrastructure around data labelling as well as how to annotate emotions in the wild and how to run experiments on a large scale using large datasets. As our final AI focus, we have built a extraordinary team of researchers that are experts in emotion recognition and deep learning based algorithms.
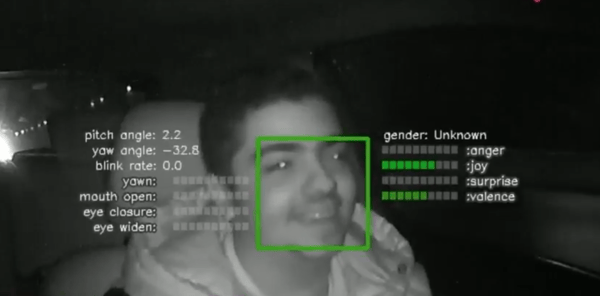
These are examples of the spontaneous data we were able to collect so far. We have created platforms that are not limited by the location of the hardware or camera. Our robust solution is also able to track faces, non-intrusively, at night or during the day, wearing face masks or glasses.
GOING DEEP INTO ALGORITHMS
For our algorithmic pipeline, a series of machine learning techniques comes in play. The first one is detecting face and tracking facial landmarks. We then want to give these faces a classification corresponding to each individual visual expression and emotion occurrence, such as joy, yaw, eyebrow raise, etc. This is not an easy task, however, because a face can generate hundreds of facial expressions and emotions.
The simplest way to feed each image to a classifier is to use single individual images at a time. Yet, only using a single image is not always enough to classify metrics - so it can actually be very misleading. Only after looking at the sequencing of images that is really possible tell if the person is just talking, yawning or even shocked, for example.
Understanding human emotional state is a continuously evolving process. When looking at a sequence of frames from an in-cabin recording, we can easily see the transition of an emotional expression from not present at all to completely evident. Interpreting that and leveraging it makes our predictions more robust and accurate. Also, another prime asset of ours is using temporal information to know what the person’s neutral state looks like so we can also get the subtle changes in the emotional state of that person.
Although Affectiva’s long road trip has just started, we already have plans for the future: as we continue our work in the automotive industry, we aim to improve our temporal models training to as well as to introduce a drowsiness intensity metric using our current facial markers: yawn, blink rate and eye closure. Watch Affectiva Technical Deep Dive to know more about the science behind out technology and the future directions of Emotion AI.
Missed our awesome webcast with Renovo about how we building the best possible automotive experience together? We have the recorded session available for you.




